End-of-turn prediction, interruption handling, and the timing tradeoffs behind natural voice AI.
.png)
We thought we solved turn-taking once our AI stopped cutting people off.
We didn’t.
In insurance tests, the system no longer interrupted — but conversations still felt broken.
Users finished speaking. → The AI waited.
→ The silence lingered just long enough to feel wrong.
People weren’t annoyed.
They were unsure.
Humans don’t say when they’re done talking.
They signal it. → Pitch shifts. → Micro-pauses. → Breath. → Rhythm.
We read these cues without thinking.
The AI didn’t.
Even with perfect transcription and correct answers, weak turn-taking made the system feel robotic.
Users would:
Nothing was “wrong.”
The timing was.
.png)
Every failure fell into one of two buckets:
Fixing one usually broke the other.
We had to solve both at once.
Silence isn’t a signal.
Context is.
“I went to the doctor and then…” isn’t finished.
“I went to the doctor.” probably is.
Early systems treated both pauses the same.
That worked until real speech showed up.
People pause to think.
To breathe.
To hold the floor.
Silence alone was useless.
Interruptions aren’t accidents.
They’re intentional.
Correction.
Urgency.
Clarification.
In healthcare especially, users cut in constantly.
If the system kept talking for even 500ms after being interrupted, trust collapsed.
Backchannels can lag.
Interruptions can’t.
When someone cuts in, the system has to stop — immediately.
Fast.
Responsive.
It tracked:
It worked for ideal speakers.
Then accents, flat intonation, and atypical rhythm broke it.
The system reacted quickly — and cut people off.
Accurate.
Context-aware.
It used:
It understood intent.
But transcription latency mattered.
Even correct responses arrived too late.
The system always felt behind.
We stopped choosing between speed and understanding.
Audio handled immediacy.
Text handled intent.
Audio might signal an ending.
Text might signal continuation.
The fused model reads both.
That balance held up in real conversations.
“um”
“uh”
“you know”
These hold the floor.
Early models heard the pause and jumped in.
We had to treat fillers as continuation markers.
Harder than it sounds — fillers vary wildly across accents.
“Yesterday I woke up early, then…
[pause]
I went to work.”
Same acoustics as a true ending.
Different meaning.
Prosody helped:
Text alone wasn’t enough.
Audio alone wasn’t either.
Too fast → interruptions
Too slow → lag
Testing gave us ranges:
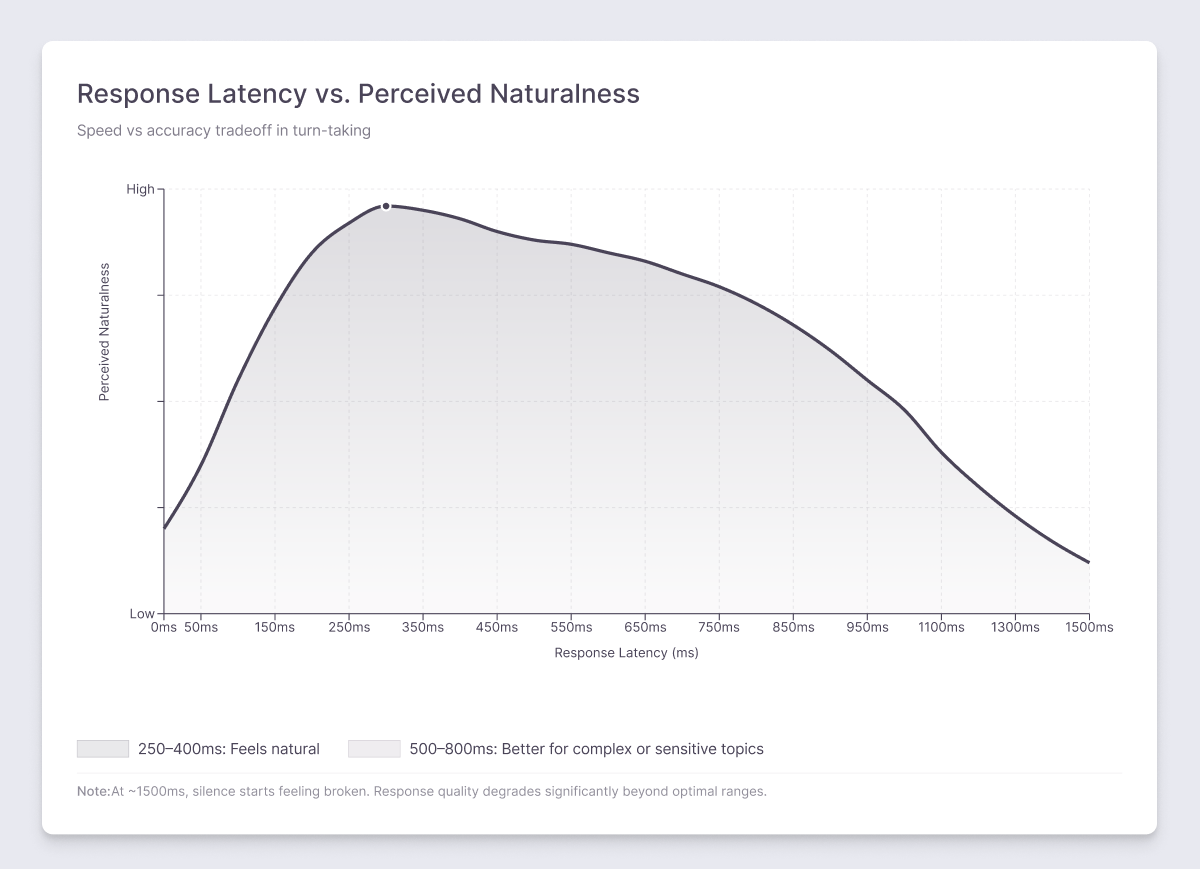
There is no universal number.
Timing has to adapt to what’s happening, not just silence.
Fast speakers sound finished early.
Slow speakers stretch turns.
Non-native speakers flatten pitch.
We saw massive regional variation.
The fix wasn’t better averages.
It was adaptation.
The system now learns a user’s rhythm within the first few turns.
By turn three or four, it’s calibrated.
Turn-taking is invisible when it works.
Catastrophic when it doesn’t.
It runs in milliseconds but depends on context built across the entire conversation.
Every new domain breaks assumptions:
We keep refining.
Current results:
At that point, users stop managing the system.
They just talk.
Join leading enterprises using AveraLabs to deliver human-level service at AI speed
.png)
© 2025 AveraLabs
