A speech-to-speech (S2S) model doesn’t translate speech into text and then back into speech. It listens, thinks, and responds in audio form end-to-end.

A speech-to-speech (S2S) model doesn’t translate speech into text and then back into speech. It listens, thinks, and responds in audio form end-to-end.
Under the hood, speech is represented as discrete audio tokens, and dialogue is generated directly in that same space.
The result?
Conversations that feel less like a pipeline, and more like… a conversation.
By contrast, the traditional voice stack looks like this:
Audio → STT → Text → LLM → Text → TTS → Audio
That text layer is both a superpower and a liability.
It gives us control, logs, and guardrails, but it also strips away tone, timing, emotion, laughter, hesitation, and all the messy signals that make speech human.
Worse, it forces conversations into clean turns, even though real people constantly interrupt, overlap, and talk over each other.
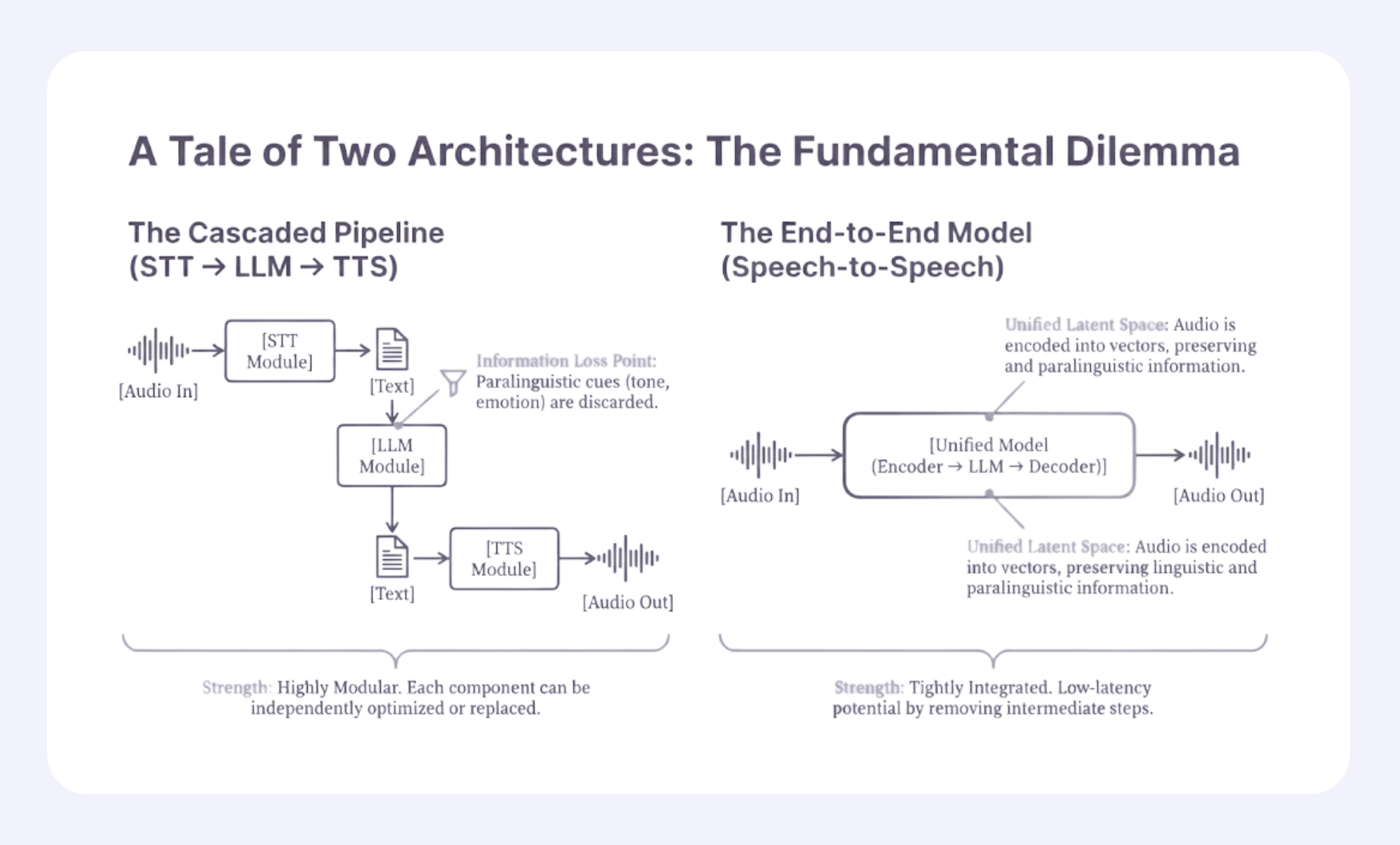
Each stage in a modular pipeline adds delay. Unified S2S systems remove those handoffs, enabling near-real-time responses.
The result is faster backchannels, smoother turn-taking, and more natural barge-in.

Meaning isn’t just in words, it’s in pitch, pacing, emphasis, laughter, and hesitation.
Once speech becomes text, most of that disappears. Speech-to-speech models keep those signals alive, leading to more expressive and socially fluent responses.
Real conversations overlap.
S2S architectures support parallel user and system speech streams, allowing interjections, interruptions, and side-channel signals without forcing clean turn boundaries.
At a high level:
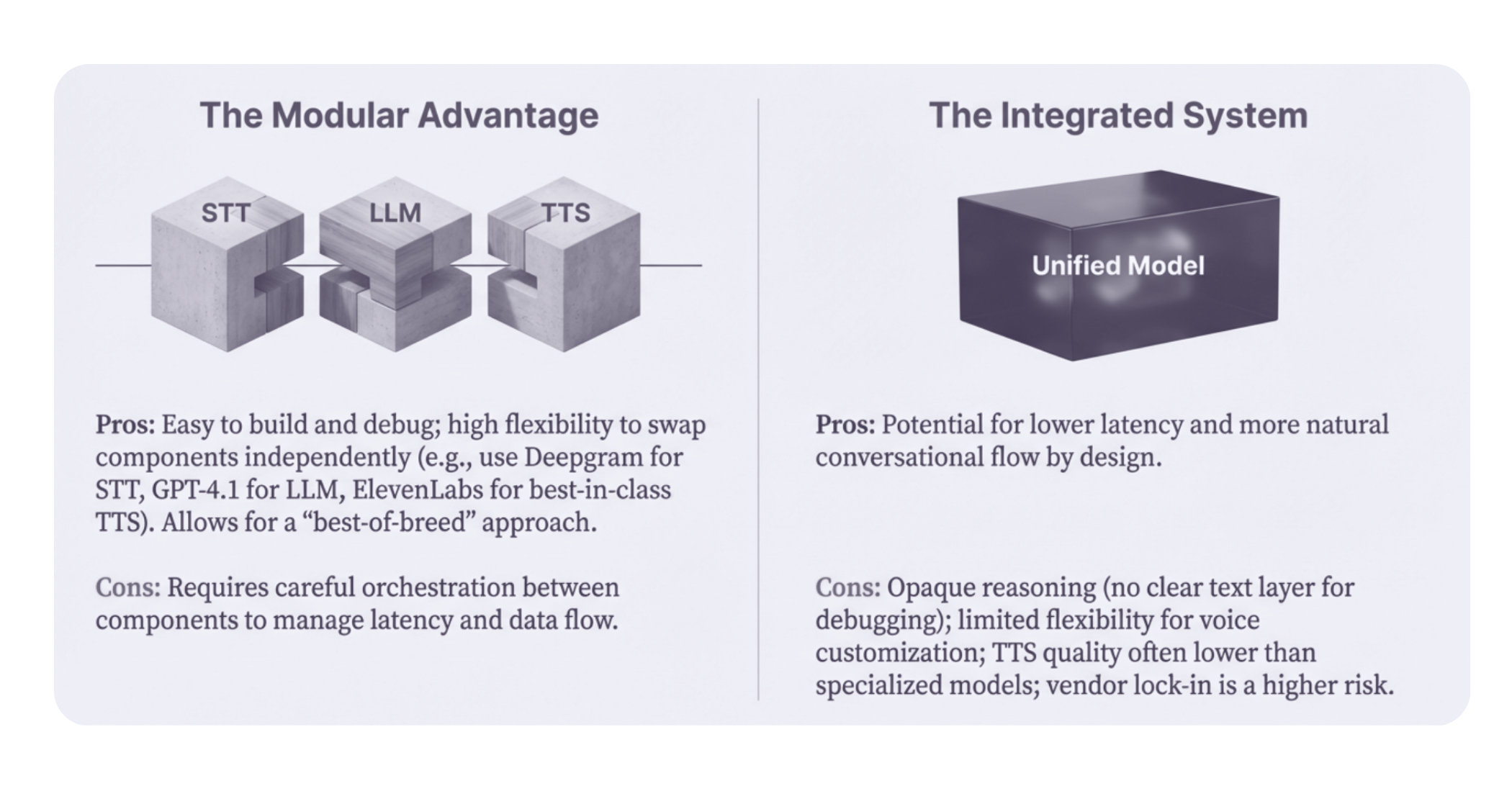
Modular systems optimize for control, whereas speech-to-speech systems optimize for interaction.
Why teams love them
Where they struggle
Best fit: Compliance-critical, high-reliability, and enterprise control-first use cases
Why teams love them
Where they struggle
Best fit: Experience-first, real-time, human-like interaction use cases
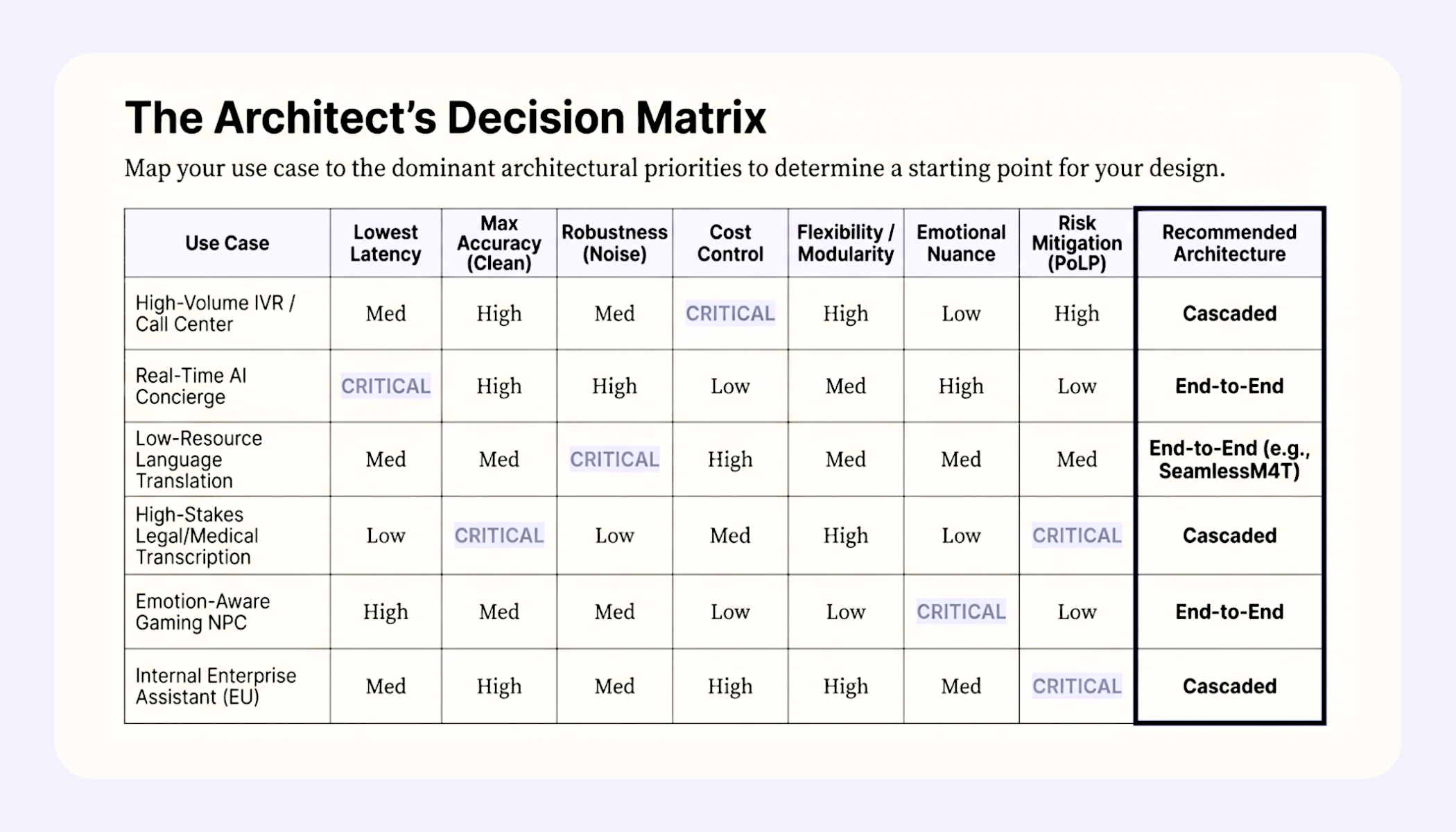
The matrix below shows that cascaded and end-to-end architectures serve different use cases.
Enterprise, compliance-driven workflows favor cascaded pipelines, while latency- and experience-driven applications favor end-to-end speech-to-speech models.
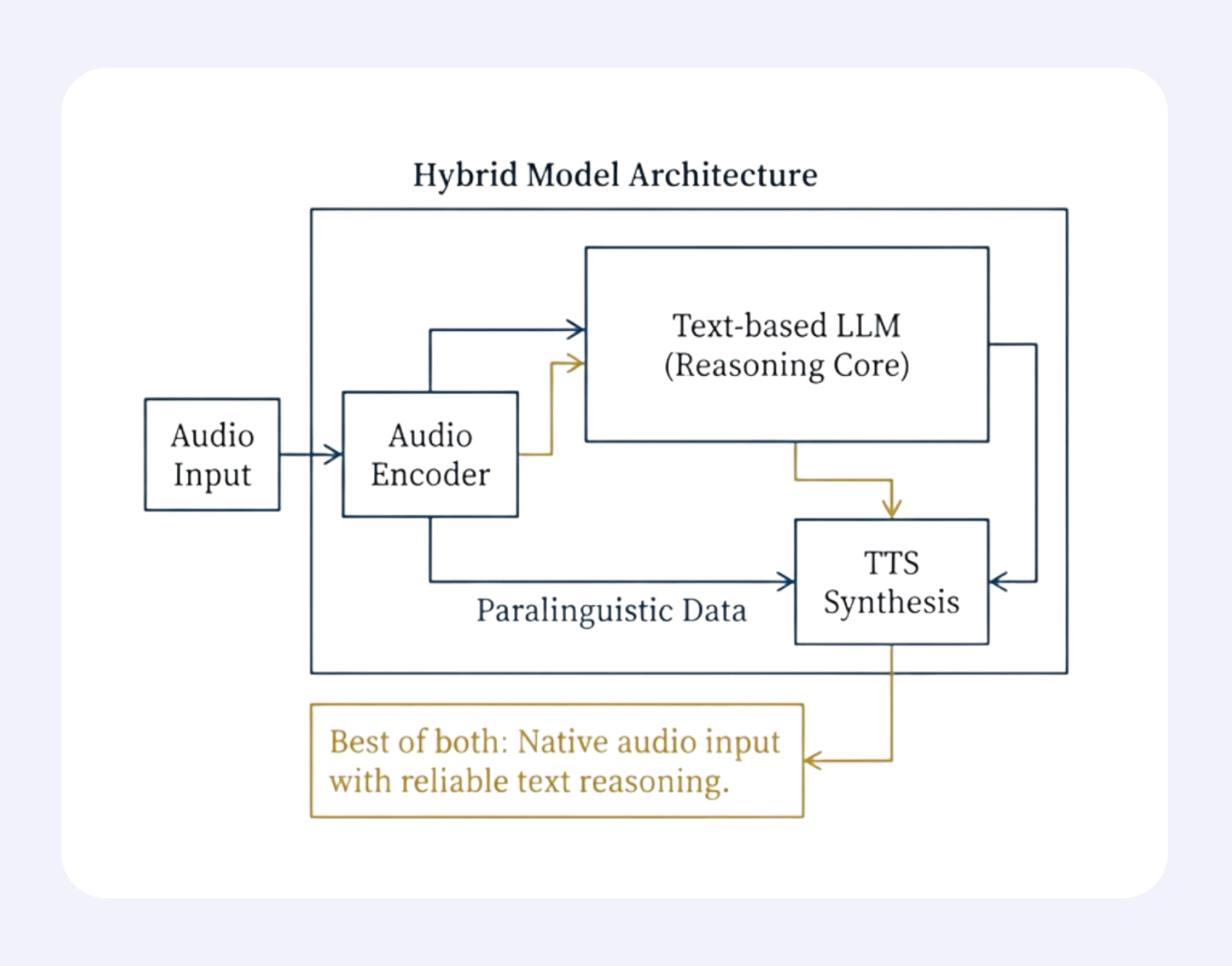
As architectural boundaries blur, the future of voice AI is moving toward designs that combine native audio understanding with reliable text-based reasoning.
These hybrid systems preserve paralinguistic richness and low latency while maintaining interpretability and control.
With real-time bottlenecks easing through targeted innovations, and high-quality audio data still scarce, hybrid architectures offer the most practical and resilient path to scalable, production-ready voice intelligence.
Join leading enterprises using AveraLabs to deliver human-level service at AI speed
.png)
© 2025 AveraLabs
