Paralinguistic cues and emotional contour explain why correct speech can still feel wrong.

We spent months perfecting our voice AI’s pronunciation and word choice.
The transcripts were flawless.
When we played recordings to testers, they all said the same thing:
“It sounds flat.”
“It feels robotic.”
Every word was correct.
The problem was everything between the words.
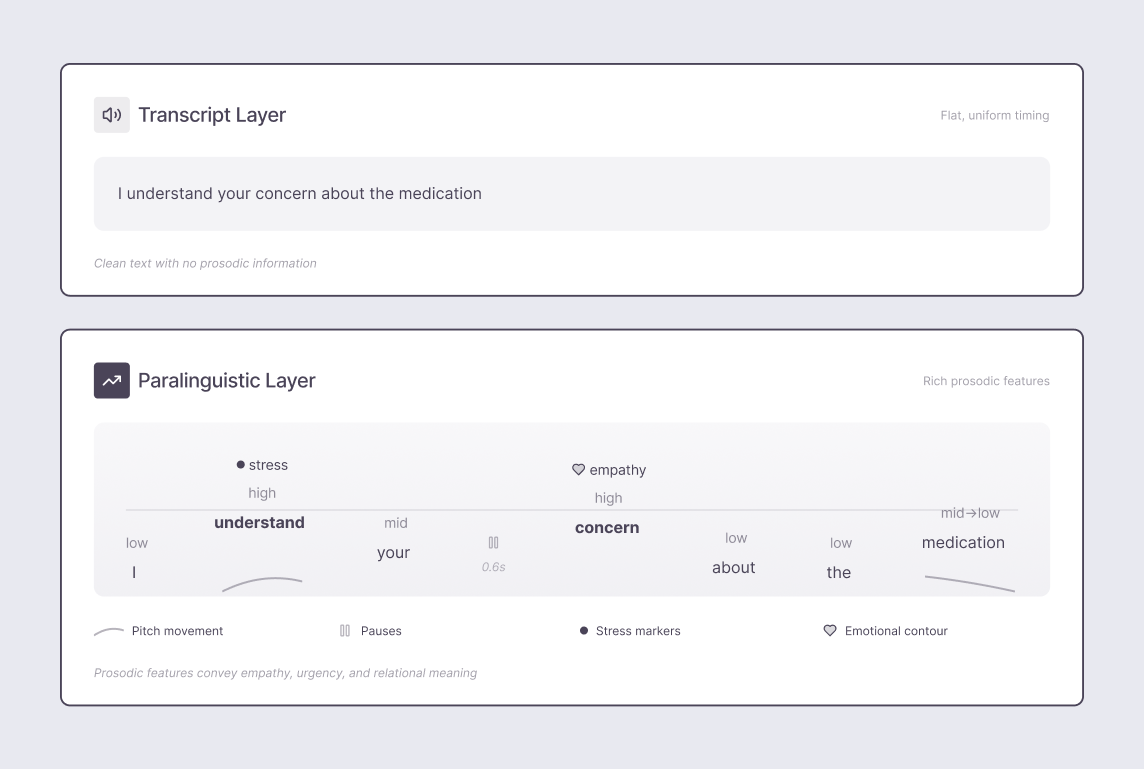
Human speech carries meaning through:
These aren’t noise. They’re control signals.
They tell listeners:
When we optimized early versions of the system for efficiency, we stripped many of these signals out.
The result sounded clean and dead.
Users described conversations as “technically correct, but something feels wrong.”
They were right.
Paralinguistic cues include:
These cues are structural.
They answer questions words alone cannot:
Remove these cues and speech collapses into something closer to reading aloud.
Listeners don’t wait to parse words before judging meaning.
They resolve ambiguity, intent, and emotion through prosody first — pitch, timing, and intensity.
Decades of research show that when emotional prosody conflicts with the emotional meaning of words, listeners trust prosody over semantics.
How something is said outweighs what is said.
We saw this clearly in insurance claims testing.
When the AI said:
“I understand this is frustrating”
with flat prosody, claimants rated it as dismissive.
Same sentence.
Different delivery.
When pitch variation and pacing matched empathy, the response was rated as genuinely understanding.
The words didn’t change.
The meaning did.
Consider “That’s great.”
Without prosody, it’s meaningless.
With prosody, it can signal enthusiasm, sarcasm, resignation, or irritation.
This is why transcripts flatten meaning.
Our system had to learn patterns humans use instinctively:
These aren’t stylistic choices.
They’re rules for how humans package intent.
Stance - sincere, sarcastic, teasing, polite, hostile - is often impossible to determine from words alone.
Prosody does the disambiguation.
Research by Cheang & Pell shows listeners reliably identify sarcasm from acoustic and prosodic cues even when lexical content stays constant.
There’s no single “sarcasm tone.”
It emerges from combinations:
These patterns generalize across languages. Even when listeners don’t understand the words, they infer stance from the signal.
Our system failed badly here.
Patients often joke to deflect anxiety about test results.
Early versions of the AI responded to the literal content of those jokes instead of recognizing them as emotional deflection.
Patients described the system as “not getting it” - even when the factual response was correct.
The AI missed the paralinguistic cues that revealed what was actually happening underneath the humor.
That failure broke trust immediately.
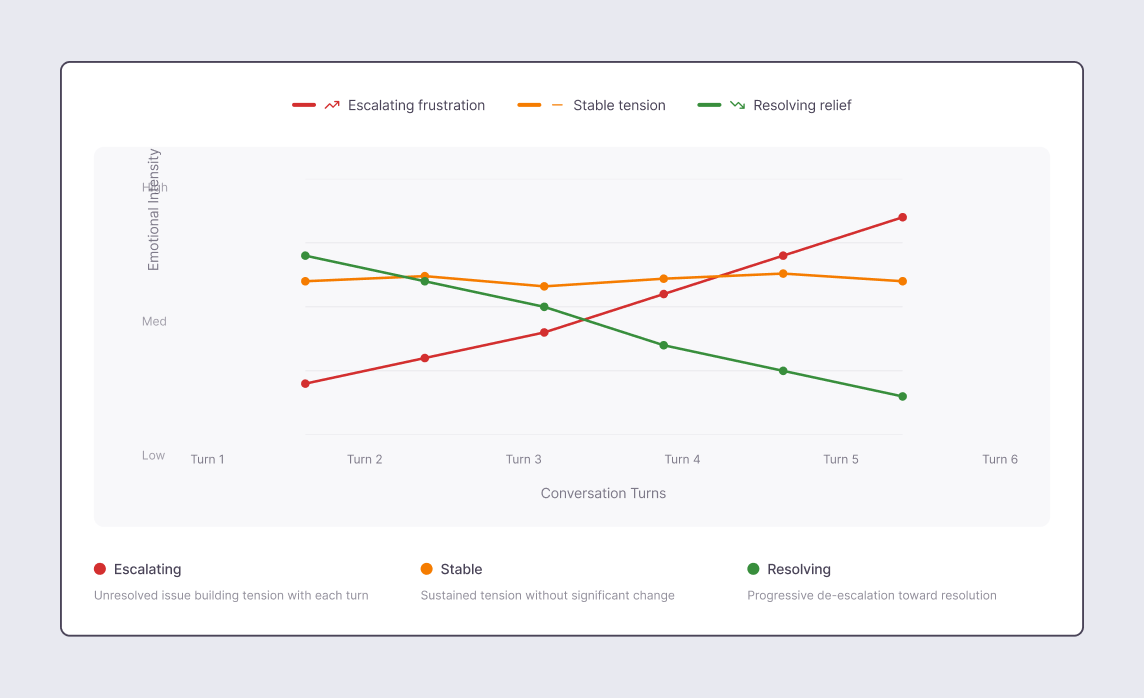
Emotion doesn’t exist as a static state.
It moves:
You hear this movement in pitch range, tempo, intensity, and pause placement.
Humans respond not to what emotion is present, but to how it’s changing.
That movement is emotional contour.
Early versions of our system tried to label emotion per turn:
This failed constantly.
Research by Scherer & Bänziger shows emotions are encoded in patterns over time, not single acoustic features.
A user might:
The labels mattered less than the slope.
We rebuilt the system to track emotional contour across entire conversations.
Instead of asking:
“Is this person angry?”
We ask:
“Is frustration increasing, stable, or decreasing?”
That change reshaped behavior:
Humans do this constantly.
So does effective conversation.
Paralinguistic cues are hardest to model because they’re automatic for humans.
We don’t think about them — which makes them invisible until they’re gone.
Every domain adds new patterns:
The system has to learn these micro-patterns to stop sounding mechanical.
In recent tests, users say conversations feel natural even when they know the voice is AI.
That gap matters.
It means the system isn’t relying on illusion.
It’s encoding meaning where humans expect it: between the words.
That’s the difference between intelligible speech and human-feeling speech.
Get those invisible signals right, and the AI becomes a conversational partner.
Get them wrong, and it stays a machine reading text, no matter how perfect the words sound.
Join leading enterprises using AveraLabs to deliver human-level service at AI speed
.png)
© 2025 AveraLabs
