Millisecond-level latency, not voice quality, makes AI feel robotic.

Our first voice AI prototype looked perfect on paper.
Speech recognition was accurate.
Audio was clean.
Responses were fast.
Every tester still said the same thing:
“It feels robotic.”
We spent two weeks reading transcripts, convinced the issue had to be what the system was saying.
It wasn’t.
The words were fine.
The problem was when they arrived.
Our system responded to every user input at exactly 180 milliseconds.
Consistent.
Efficient.
Completely unnatural.
Humans don’t respond at fixed speeds.
If someone asks, “Are you still there?” you answer almost instantly.
If someone asks, “Why did you quit your job?” you pause — because the question carries weight.
That pause is not dead time.
It communicates hesitation, thoughtfulness, and emotional gravity.
Our AI treated every question the same.
That uniformity broke the rhythm people expect from real conversation.
Classic research by Sacks, Schegloff, and Jefferson found that the average pause between conversational turns is only ~200 milliseconds.
That’s faster than most people can consciously plan a sentence.
Which means something counterintuitive:
We’re not waiting to finish thinking before we respond.
We’re anticipating.
While someone is still talking, we’re already preparing our reply.
That predictive ability is what makes conversation flow.
Chimpanzees, by contrast, need close to a full second to respond in vocal exchanges.
They don’t anticipate turn endings the way humans do.
We’ve evolved to be fast.
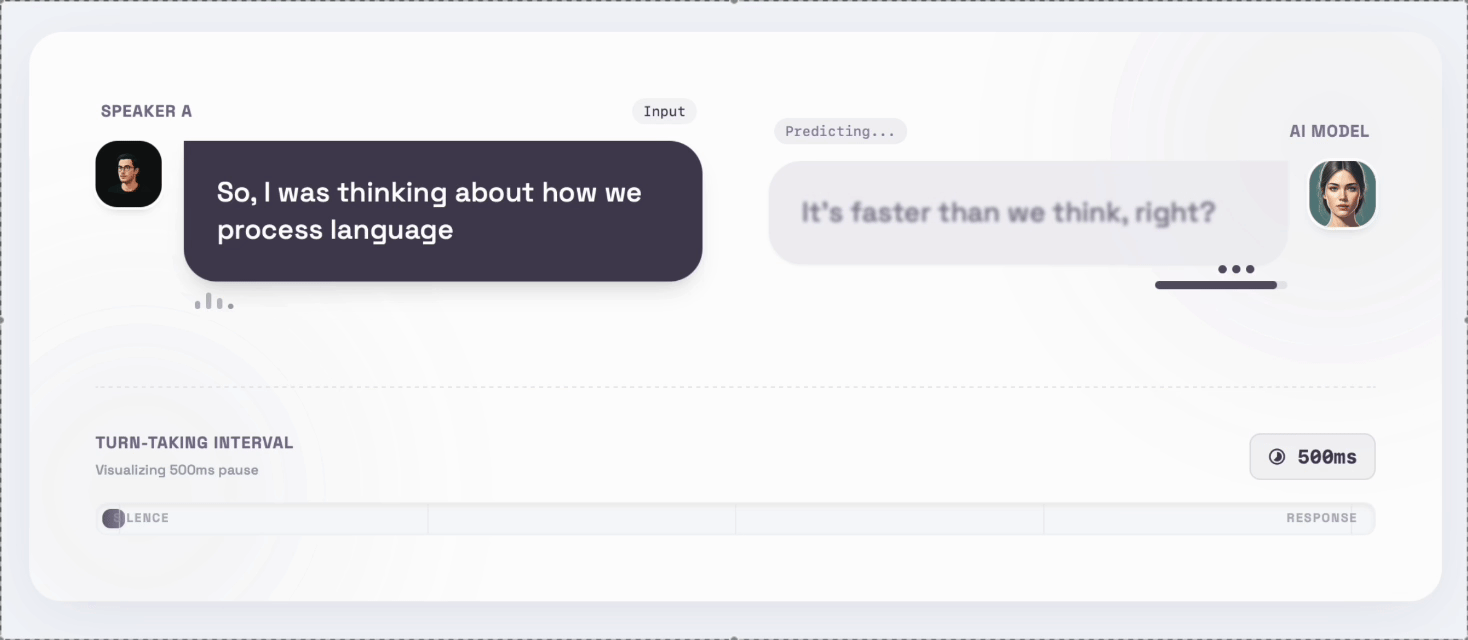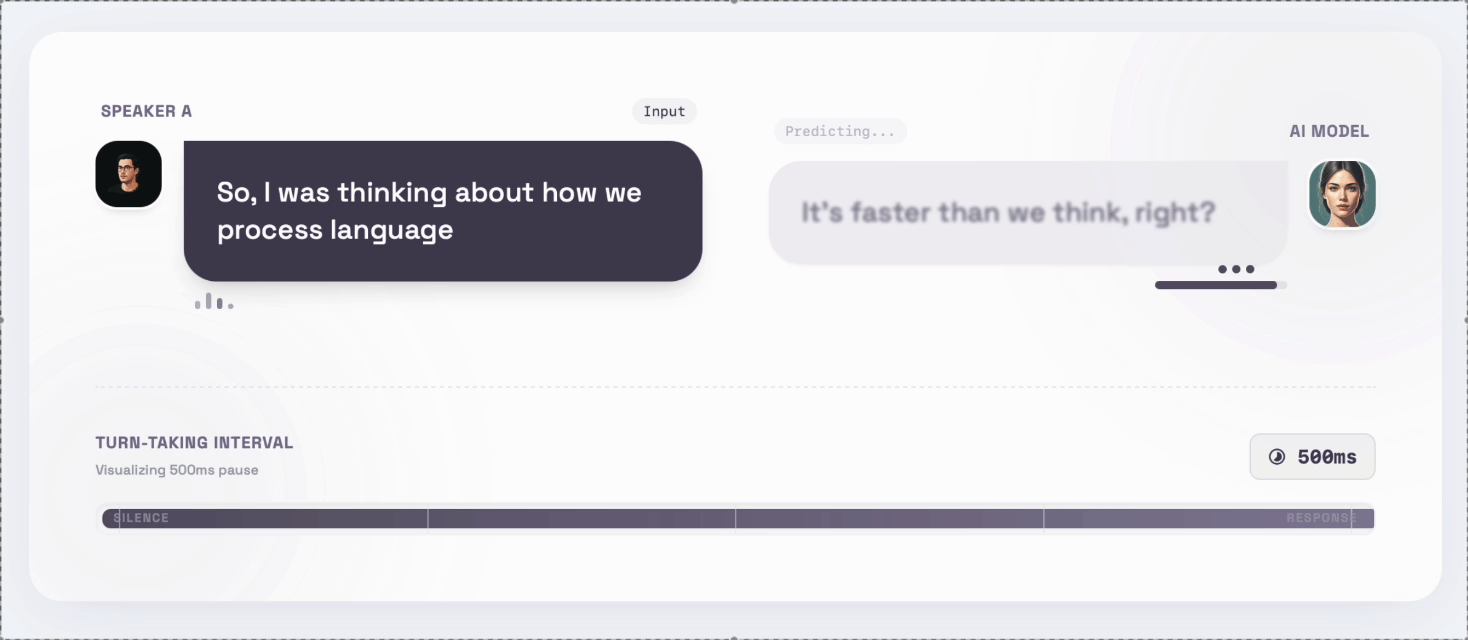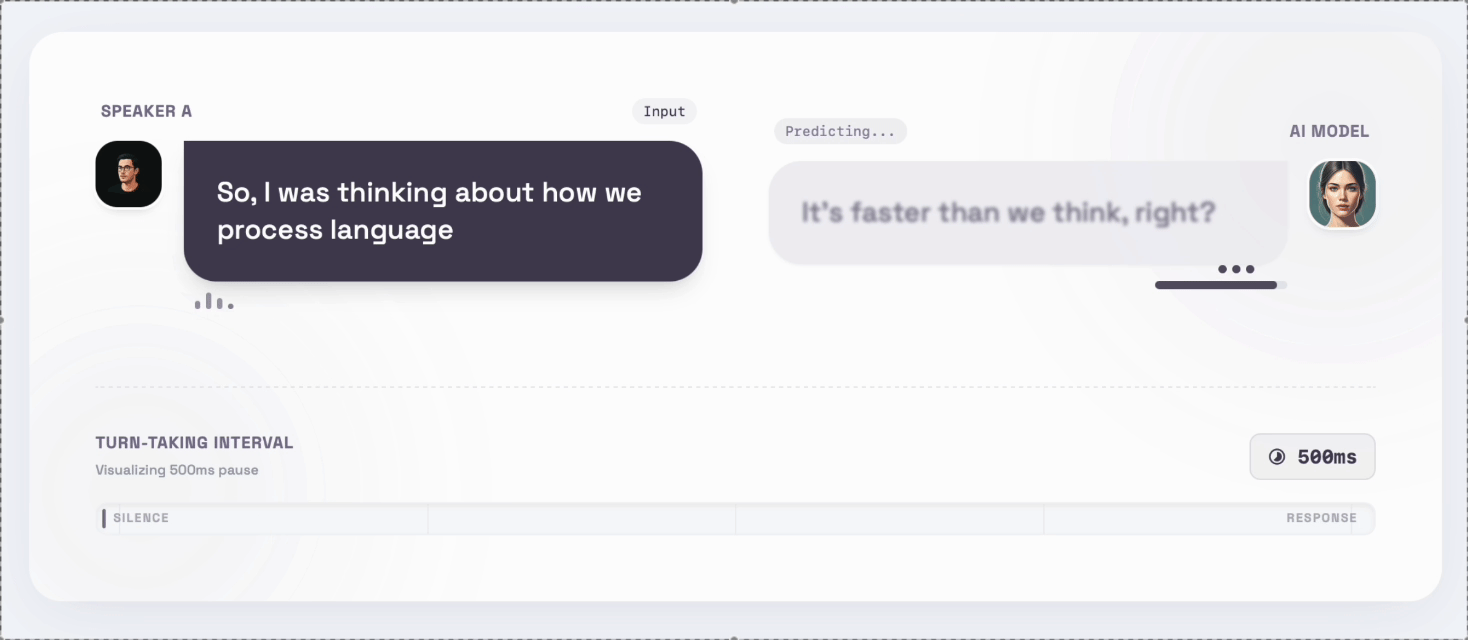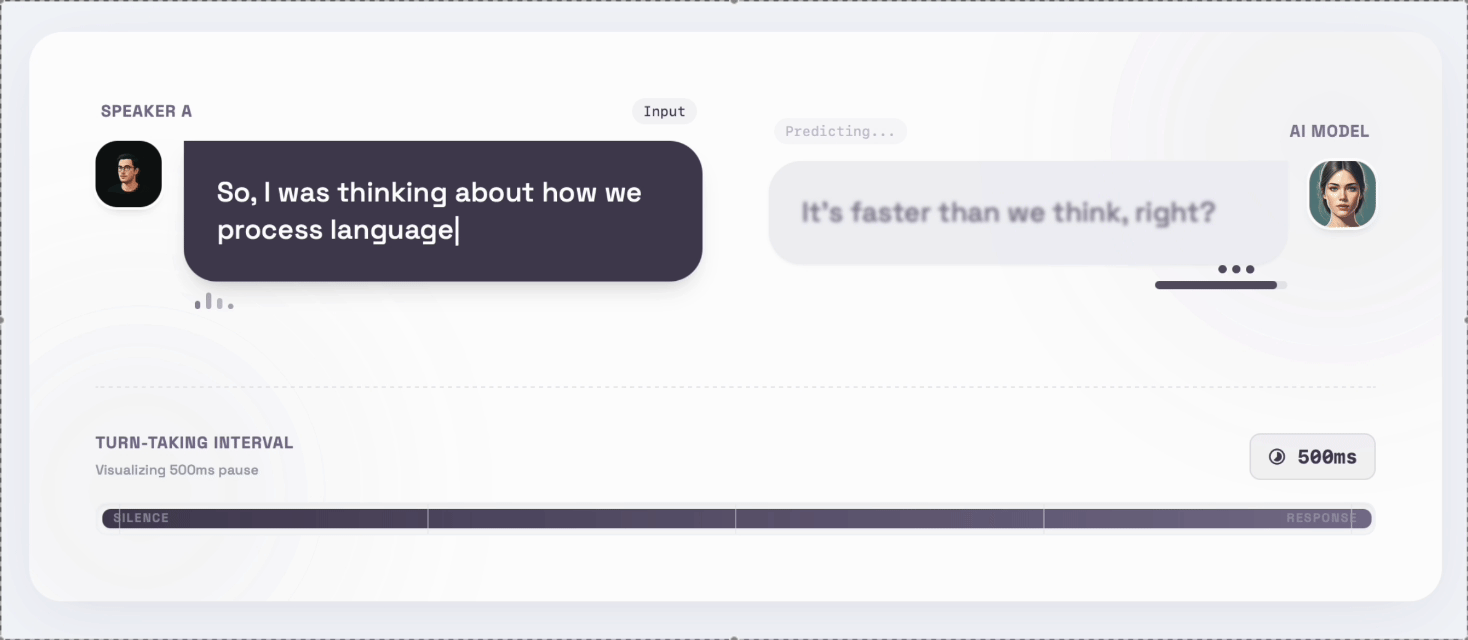
We tested this directly.
When our system waited even 500 milliseconds after a user finished speaking, testers described it as:
“Laggy.”
Half a second should feel instant.
It doesn’t — because real conversation has momentum.
Once that momentum drops, the AI stops feeling conversational and starts feeling like a tool struggling to keep up.
At that point, it doesn’t matter how good the words are.
The interaction already feels off.
Audio examples:
Small acknowledgments like:
“yeah”
“right”
“mm-hmm”
aren’t filler.
They’re signals that say: I’m with you.
Research by Gravano & Hirschberg and Ward shows these need to land within 50–250ms to feel natural.
After 500ms, the exact same “mm-hmm” is judged as inattentive or even rude.
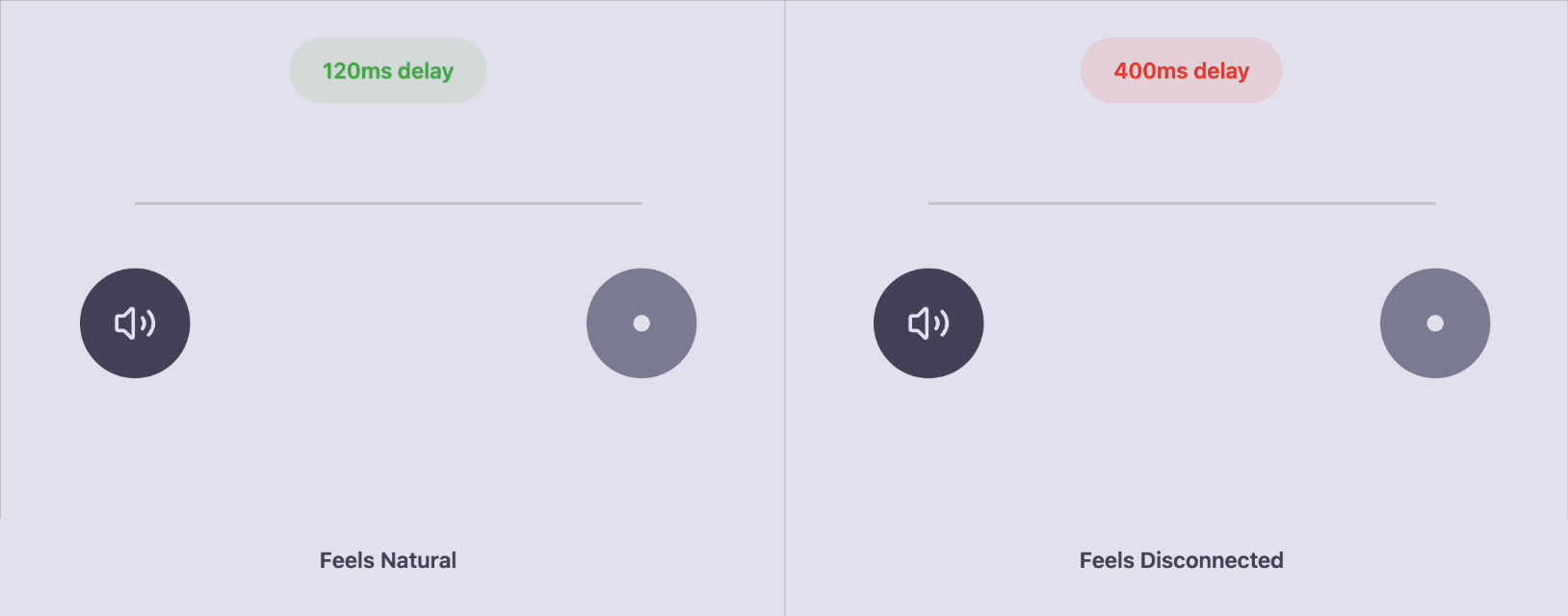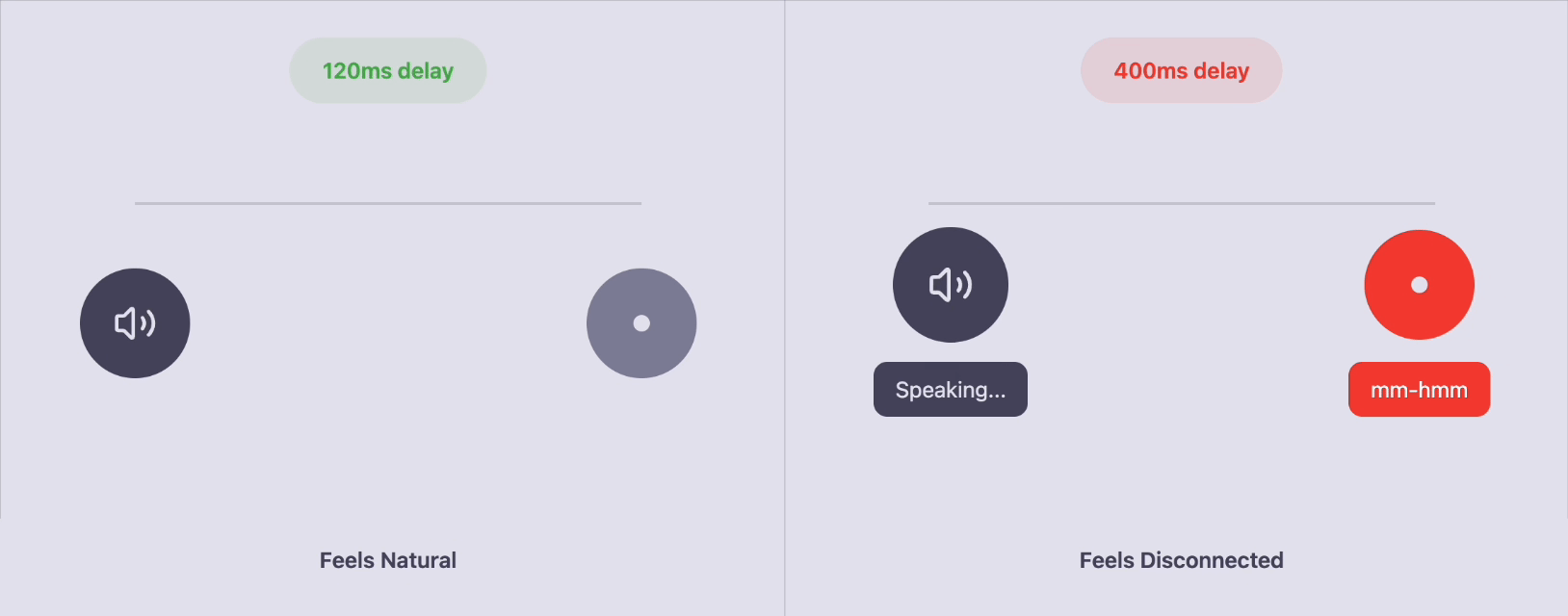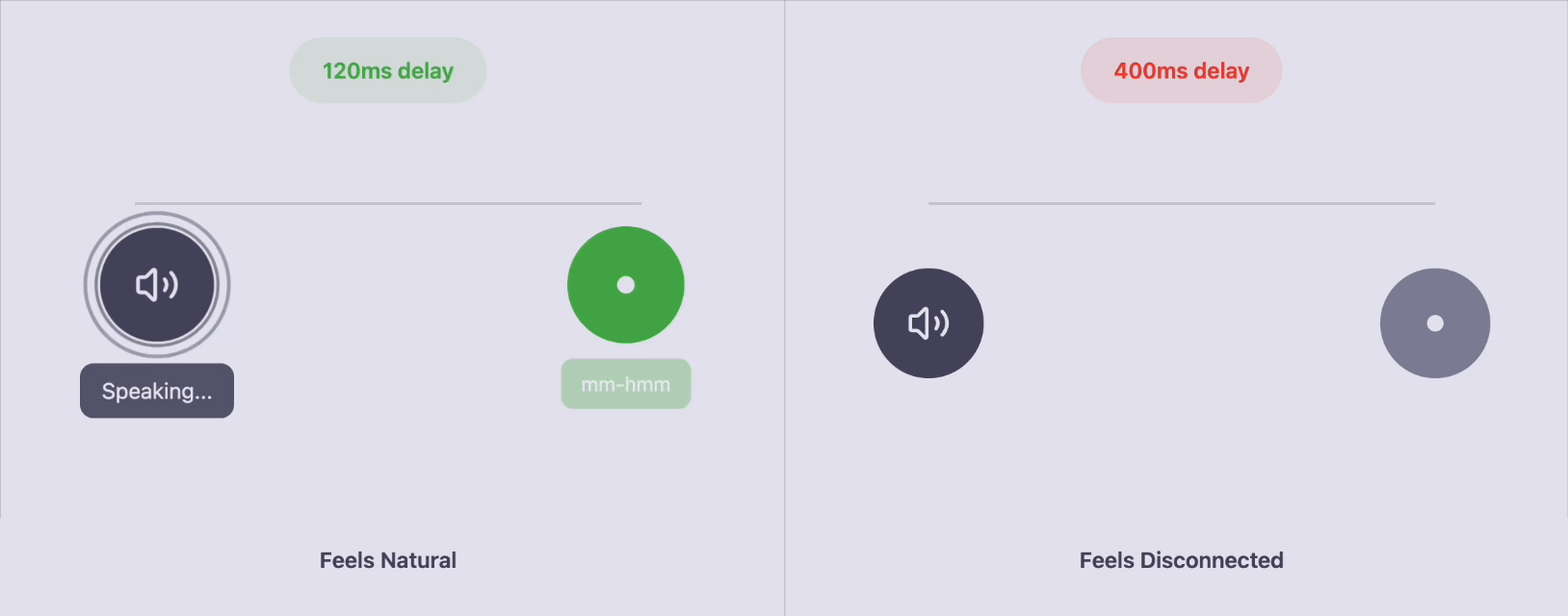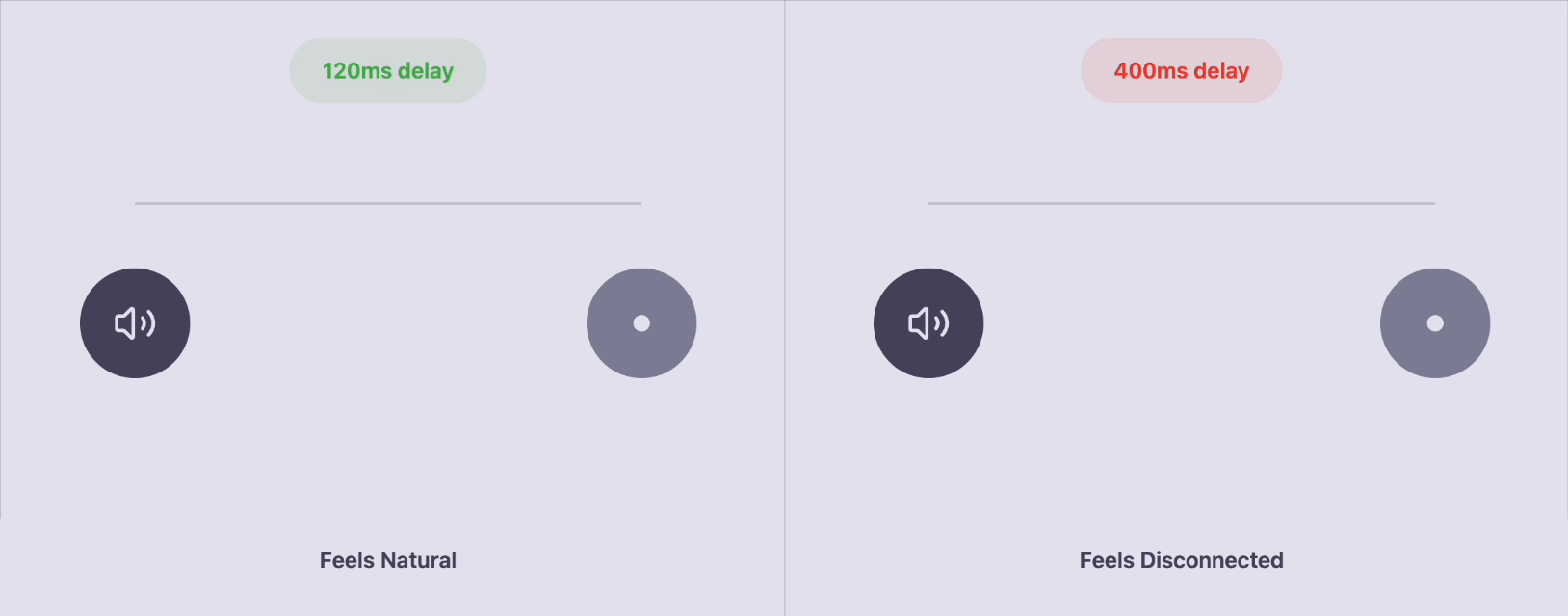
We saw this clearly when testing with insurance agents.
An agent would say:
“So the claim was filed on Tuesday…”
Our AI replied with “mm-hmm” at ~400ms.
Technically fast.
Consistently rated as disconnected.
The delay made it feel like the AI had zoned out.
That’s when we realized:
Backchannels can’t go through the same pipeline as full responses.
They need reflexes, not deliberation.
Audio examples:
Speed isn’t always better.
A 2023 USC/MIT study found that pauses in the 500–1200ms range made responses feel more thoughtful and emotionally aware.
Instant replies to serious questions were judged as scripted or shallow.
We saw the same pattern in healthcare testing.
When patients asked sensitive questions about treatment options, immediate answers felt dismissive.
Adding a deliberate pause before delivering complex medical information made the same words feel careful and empathetic.
Counseling research shows humans naturally lengthen pauses by 30–70% when topics become emotionally charged.
The slowness itself communicates care.
Audio examples:
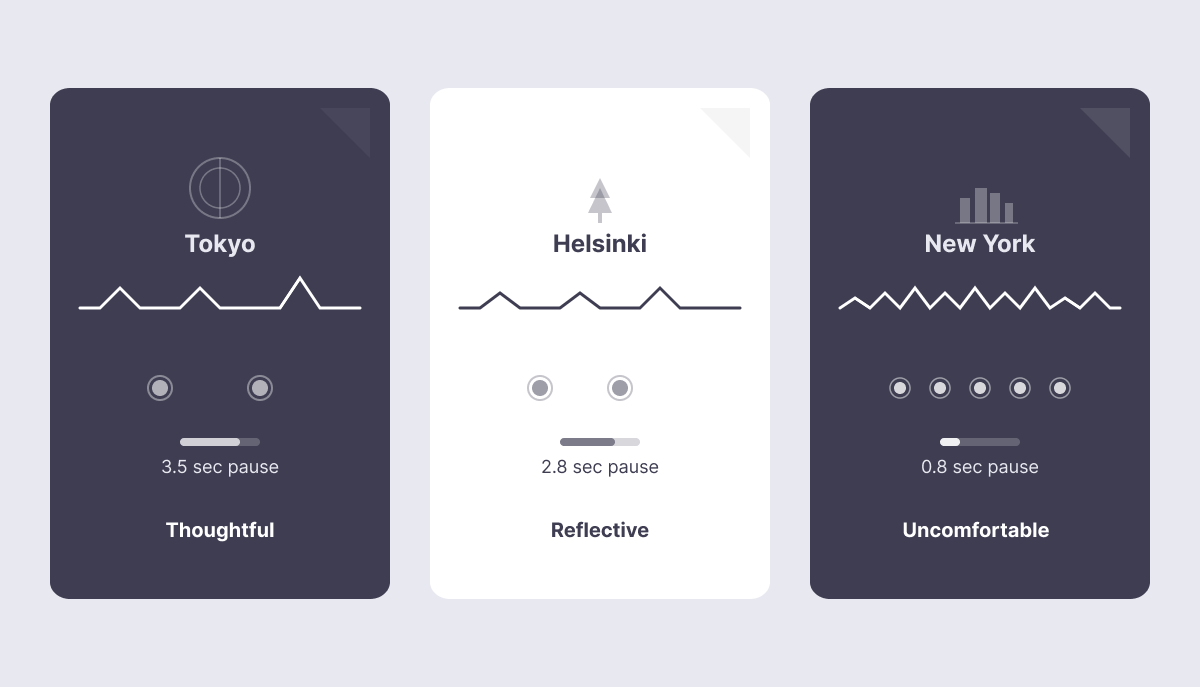
Cross-linguistic research found that while every culture tries to minimize conversational gaps, each one has its own internal rhythm.
Japanese speakers use pauses more freely and often interpret them positively.
Americans read the same silence as awkward or uncomfortable.
One study found that a 4-second silence made American managers visibly uneasy, while Japanese participants were comfortable with 8+ seconds, using the time to think.
A one-second pause can feel:
This became a real problem once we worked with insurance companies serving diverse populations.
A single timing profile might feel natural in one context and wrong in another.
There is no universal “correct” speed.
Longer pauses can feel reflective — but only up to a point.
In internal testing, we saw a sharp cliff around 1500ms.
.png)
Beyond that threshold, users began to:
AI intelligence ratings dropped sharply.
Silence stopped reading as thoughtfulness.
It read as something broken.
Keeping latency under ~1200ms preserved conversational flow.
Crossing 1500ms triggered the same frustration people feel when a call drops mid-sentence.
Example:
A voice agent that responds at the same speed every time is like a musician who only knows one tempo.
It can hit the right notes.
It can’t make music.
What we learned is that naturalness isn’t built from words.
It’s built from milliseconds.
The gap between when someone stops speaking and when you respond carries meaning.
Get that gap wrong, and even perfect language sounds fake.
The challenge is that “right” timing depends on:
Making AI sound human meant doing something software rarely does well:
Learning when not to be efficient.
We had to teach the system to hesitate, to slow down, to break consistency.
Those milliseconds make code look sloppy —
and conversations feel real.
We’re still refining the timing. Every new domain exposes patterns we didn’t anticipate.
But now, users focus on what the AI is saying — not how fast it responds.
And when timing disappears from notice, conversation finally works.
This is Part 1 of a five-part series on why voice AI still feels robotic:
Join leading enterprises using AveraLabs to deliver human-level service at AI speed
.png)
© 2025 AveraLabs
