Perfect transcription isn’t enough. This post breaks down how topic, social role, and culture determine how voice AI should sound.

We thought we’d cracked natural conversation once our voice AI started getting the words right.
Then we tested it in the real world.
Same system, used by:
Same voice. Same pacing. Same tone.
Every tester said it felt wrong.
The issue wasn’t accuracy.
It was context.
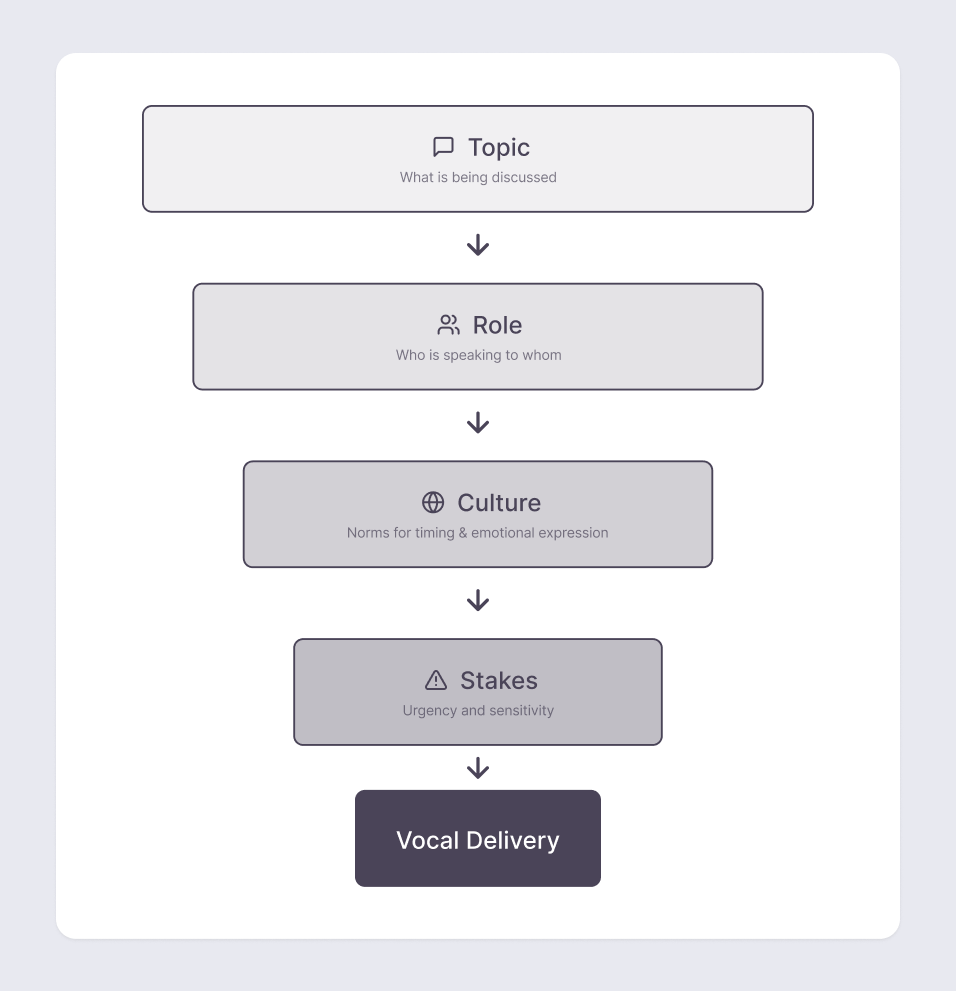
Explaining medication instructions requires a different delivery than reading policy numbers. Our AI didn’t adapt — it spoke the same way everywhere. That sameness is what made it sound mechanical.
Conversation isn’t just language. It’s adaptation.
Humans change delivery based on topic:
Linguistic research shows that prosody — pitch, rhythm, emphasis — encodes how information fits into a situation. Listeners rely on these contours to judge importance, urgency, and whether something is routine or critical.
We saw this in insurance testing: coverage explanations came out with the same energetic “greeting voice.” Agents described it as “trying too hard” and “not taking it seriously.”
The words were correct. The delivery violated the topic.
Once we added topic detection + prosody adjustment, the same words stopped feeling generic.
Conversation is relationship management expressed through speech.
Communication Accommodation Theory (CAT), developed by Howard Giles, shows that people constantly adjust their speech to converge with or distance themselves from others based on social goals.
We modulate:
These shifts change whether someone sounds competent, warm, or authoritative.
Our AI used the same friendly, casual tone with doctors that it used with patients. Doctors rated it as unprofessional.
Humans don’t do this:
When our AI used a single persona everywhere, it violated how humans encode hierarchy through speech. CAT research consistently shows that failing to adapt vocal style to social role leads to worse interpersonal outcomes — even when the message is correct.
We fixed this by adding role detection: analyzing what’s being discussed, who’s speaking, and what relationship they have.
A voice AI talking to a patient must sound different than one talking to their doctor — even when discussing the same condition.
Even when the scenario is identical, culture changes how conversation should work.
Cross-cultural pragmatics research shows large differences in:
Japanese speakers use frequent backchannels to signal engagement. American speakers use fewer, placed later. A backchannel rate that feels attentive in one culture feels interruptive in another.
We saw this when an insurance company expanded to bilingual customers.

Timing that worked for English-speaking Americans felt wrong to Japanese-speaking users who expected more frequent acknowledgment.
Same system. Same flow. Different experience.
Emotion norms also differ: some contexts expect expressive empathy, others expect calm restraint. Even “no” changes shape — hedges and delays vs directness.
Research shows listeners judge conversational appropriateness largely through timing and prosody, not just words.
So a natural voice agent doesn’t just translate text.
It adapts how it listens, pauses, acknowledges, apologizes, and expresses emotion.
Good voice quality helps. It’s not enough.
Humans adapt unconsciously. We don’t think:
“This is medication, slow down”
“This is my boss, be more formal”
Our brains do that automatically.
Teaching an AI to do this meant making context explicit:
It still makes mistakes: contexts overlap, cultures differ, edge cases keep appearing. But we crossed a meaningful threshold:
Users stopped saying “robotic.”
They started saying “that response was appropriate / inappropriate for this situation.”
That’s the point. The goal isn’t “sound nicer.”
It’s do the invisible work that makes conversation fit the moment.
Join leading enterprises using AveraLabs to deliver human-level service at AI speed
.png)
© 2025 AveraLabs
